Pushing Edge AI to the Precipice
Deep neural networks are a powerful tool for extracting information from raw sensor data. But the severe memory and computational constraints of an embedded sensor mean that deep neural networks are generally implemented on high-end cloud compute servers. This entails transmitting a continuous stream of raw data from the sensor to the cloud, which brings disadvantages like short battery life, high latency, and data privacy vulnerability.
Recognizing this problem, several engineering groups have introduced solutions to enable “edge AI”, where neural networks are directly implemented on the sensors. But these solutions rely on heavy-duty microprocessors and DSPs that burn anywhere from 0.5 W to a whopping 30 W of power. This is impractical for a large class of ultra-low power applications (e.g. self-powered sensors) that barely have 10 mW to spare.
Embedded Gated Recurrent Unit
Embedding deep neural network models within the extreme constraints of small, power-efficient microcontrollers is an increasingly active area of research. In this article, we examine the embedded Gated Recurrent Unit (eGRU), which is a version of the GRU that was optimized for ARM Cortex-M0+ microcontroller implementation. The eGRU exploits a number of modifications (see Fig. 1), each of which we will now consider in turn.
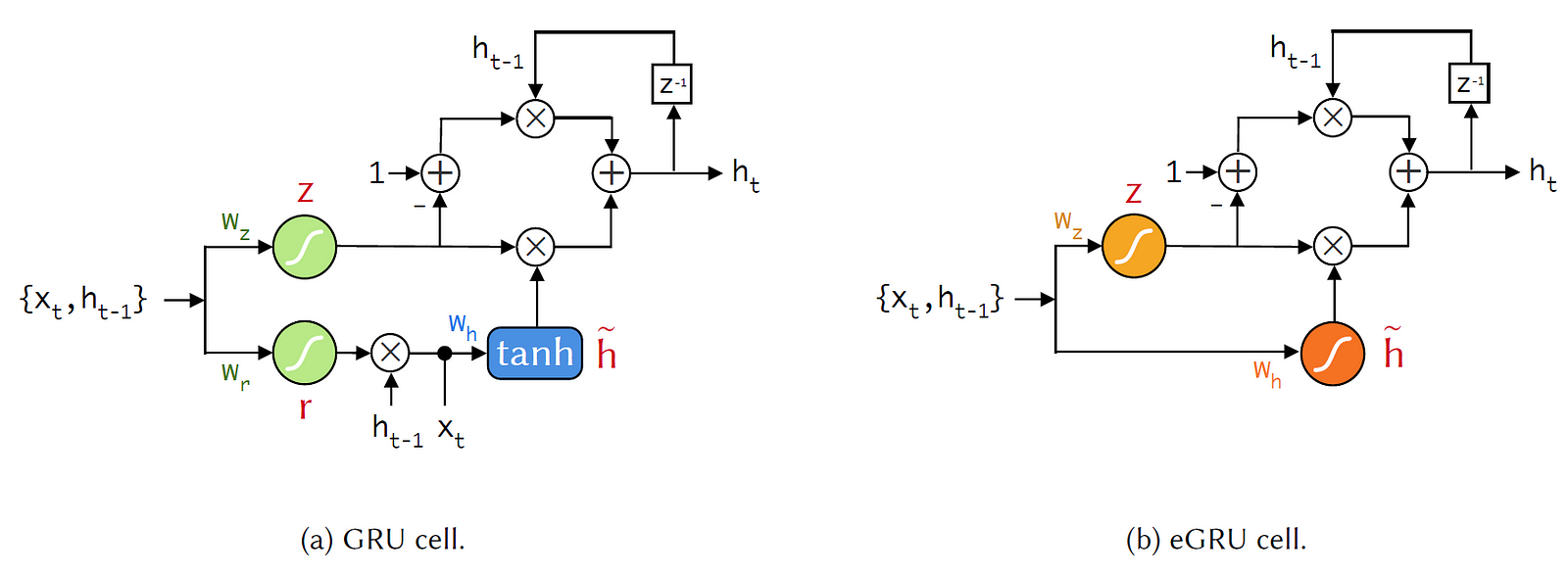
Single Gate Mechanism
The eGRU has an update gate but no reset gate. This reduces the model’s footprint by a third. Now, without a reset gate, the eGRU is prone to latch-up when presented with certain large inputs. This challenge is mitigated during backpropagation training: during the forward pass of each iteration, the eGRU states are initialized from a uniform random distribution. This forces the eGRU to discard past memory whenever any new, relevant data is presented.
Softsign Activation Function
The Cortex-M0+ has no dedicated floating point unit, making the softsign a desirable alternative to the conventional GRU’s tanh and sigmoid activation functions. The rectified linear unit (ReLU) is an even more efficient activation function, but combining ReLU with heavily-quantized weights would ruin the network’s performance. So, softsign is a good compromise: its saturating property helps maintain network performance, and it runs more than 10X faster than either the tanh or sigmoid on the M0+.
Weight Quantization
The eGRU stores its weights with a 3-bit exponential quantization code, reducing the network’s footprint by 10X.
Q15 Fixed Point Arithmetic
To conform to the M0+ 32-bit architecture, the eGRU performs all arithmetic using the Q15 16-bit fixed point format. Weight multiplications, the most frequent operations, are implemented as right-shift operations thanks to the exponential weight quantization. This contributes to a 20X increase in speed.
Evaluating the eGRU
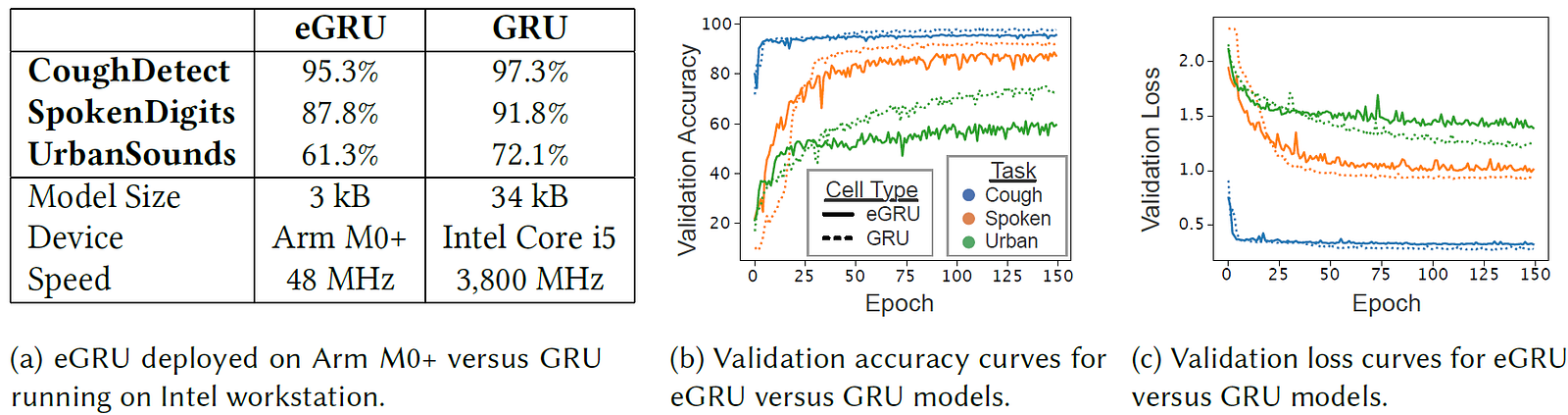
The eGRU has been evaluated on three Acoustic Event Detection (AED) tasks of varying complexity: cough detection, spoken digit recognition, and urban sounds recognition (see Fig. 2).
Compared to a traditional GRU implemented on a workstation, the eGRU implemented on an ARM Cortex-M0+ performs comparably well on cough detection, and slightly worse on the spoken digits task. The eGRU’s performance on the urban sounds task is substantially worse than the traditional GRU’s (see Fig. 3).
As it currently stands, the eGRU is effective for short acoustic event detection or keyword spotting tasks embedded on a low power microcontroller unit.

Interested in sources? Check out our original paper.
Interested in tea? This article pairs well with Earl Grey.