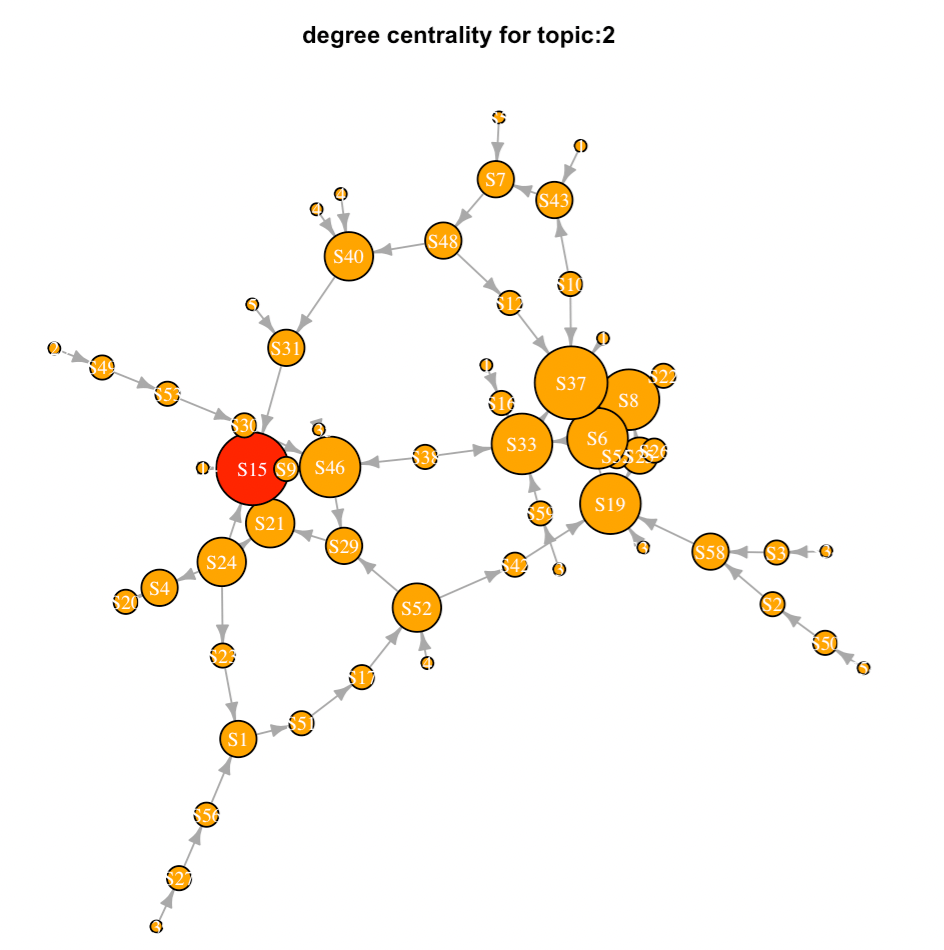

An overview of course participants’ discussion contributions in Dartmouth Introduction to Italian Opera MOOC course (link to the course)
The discussion contribution is defined as:
- posting a new thread,
- replying to a new post, and
- commenting on a reply
https://public.tableau.com/profile/publish/MUSX/MUSX
———————————————————————————————————-
An overview of user participation results in Dartmouth Environmental Science MOOC course – Introduction to Environmental Science:
https://public.tableau.com/profile/publish/ENVSXEvents/ENVSXQuizEvent
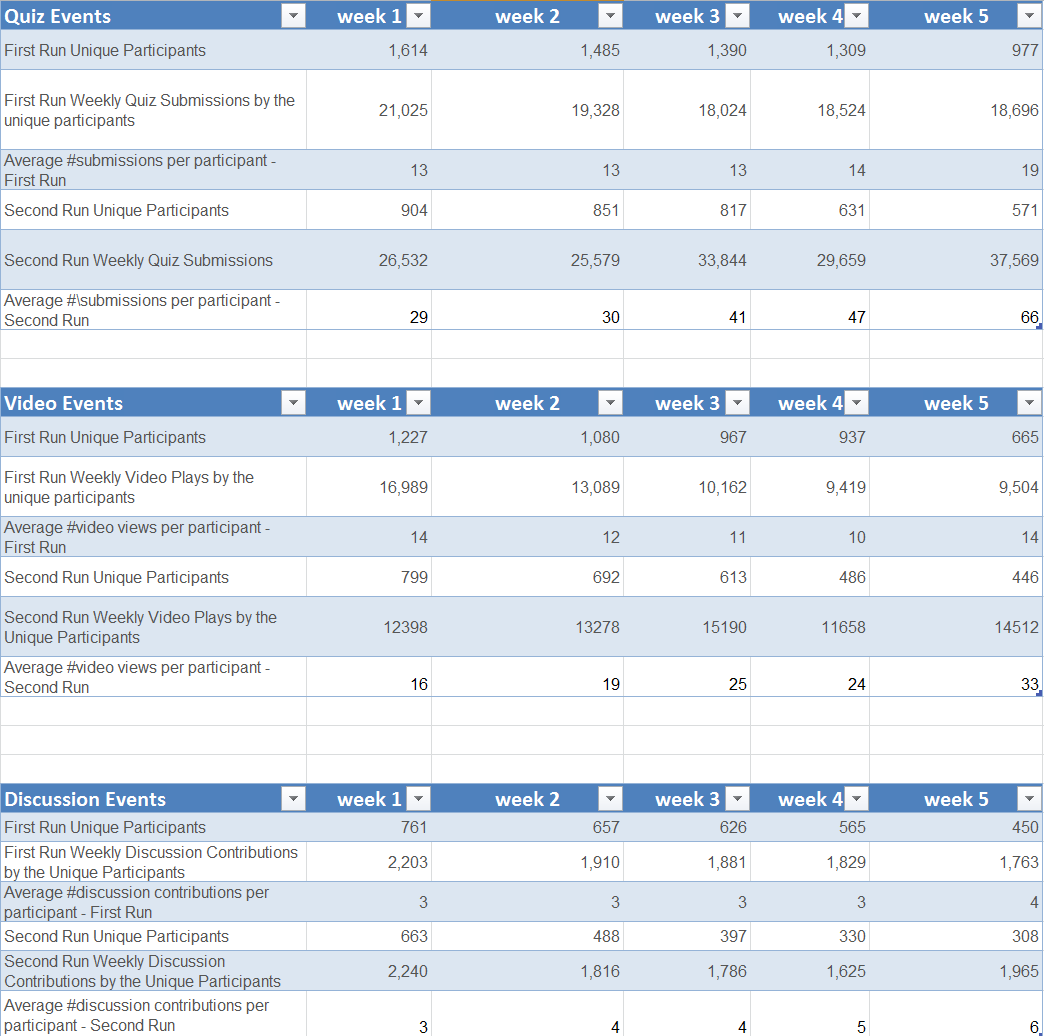
For the purpose of this study, we defined quiz submissions, video views and discussion contributions as indicators of MOOC activity engagement. The number of each activity conducted by individual participants was collected. We compared participant engagement results derived from ENVSX first run and second run. The preliminary result shows that the engagement rates of quiz submissions and video plays in ENVSX second run are significantly greater than those engagement rates yielded in ENVSX first run, even though there were less participants in second run. Furthermore, higher percentage of course participants in ENVSX second run contributed discussion activity compare to ENVSX first run and the discussion engagement rate (average #new posts/replies/comments per participant) in ENVSX second run is also higher.
The result suggests that ENVSX second run is more successful in engaging students in course activities, including quiz submissions, video views and discussion contributions respectively.
- quiz engagement rate = total #quiz submissions / #unique participants
- video engagement rate = total #video plays/#unique participants
- discussion engagement rate = total #discussion contributions/#unique participants
 ——————————————————————————————————–
——————————————————————————————————–
An overview of user participation results in Dartmouth Engineer Science MOOC course -The Engineering of Structures Around Us:
- Quiz Submissions
- Video Plays
- Discussion Contributions
https://public.tableau.com/profile/publish/ENGSXEvents/ENGSXDiscussionContribution