Author: Monica Erives, Digital Library Fellow
It may be cold and icy outside, but for the Remix team it’s harvest season! We are getting cozy with Outwit Hub, a web scraping software application, whose unofficial motto is “Harvest the Web.”
The tool is designed to help researchers extract data from web pages all tangled up in the structure of HTML code and output them in organized formats. Built in a web browser, you can browse the web within the application as you explore sites from which you want to extract data or navigate to files stored on your computer. Once you navigate to a web page or file, Outwit Hub automatically dissects it into its different elements – tables, lists, text, links, images, documents, etc. For more complicated extractions, a custom scraper can be built by utilizing patterns in the HTML and that’s exactly what we’re doing!
But why are we doing this you ask?
For some time the Remix team has been in possession of remnants of the now defunct Imagining History Portal, which you can now only view using the Wayback Machine. The portal was a collaborative compilation of research data on the existing manuscripts and fragments of the Brut chronicle at libraries across the globe (View the digitized Dartmouth copy of The Brut Chronicle). The remnants of this portal include copies of the HTML code for each of the research records. In an effort to revive the portal into a working database of manuscript research, we first have to turn messy HTML files into organized data collections that can be manipulated and uploaded to a new working site (ideally avoiding a painstaking copy/paste job).
Enter James Adams, Data Visualization Librarian at Dartmouth. James introduced us to Outwit Hub and, well, you can see the results for yourself!
Before

HTML file for one manuscript record
After
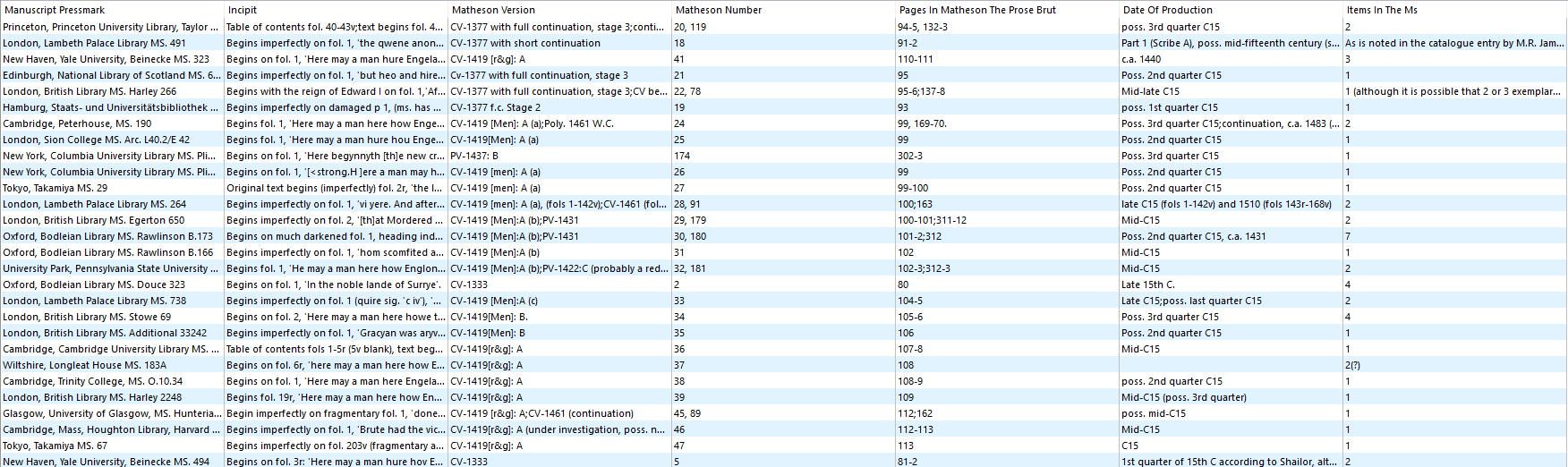
A collection of 135 records scraped from their corresponding HTML files and presented in an organized table format
In order to accomplish this, we built a custom scraper by carefully selecting the HTML markers before and after the content we wanted scraped. In the example below, in order to scrape the “Manuscript Pressmark” text from the HTML (text highlighted), we entered <h2> and </h2> in the “marker before” and “marker after” fields. The scraper then finds those html elements and grabs the text between them. Note: This simple example only works because, in this case, there is only one instance of an <h2> heading element per page. For most other content, the markers are longer to maximize uniqueness and enable the scraper to pinpoint the correct data.
Once all of the markers are set up for a single web page/record, the scraper can be applied to all 135 records, resulting in an organized spreadsheet of field names and descriptions and bringing the Imagining History Portal one small step closer to life!
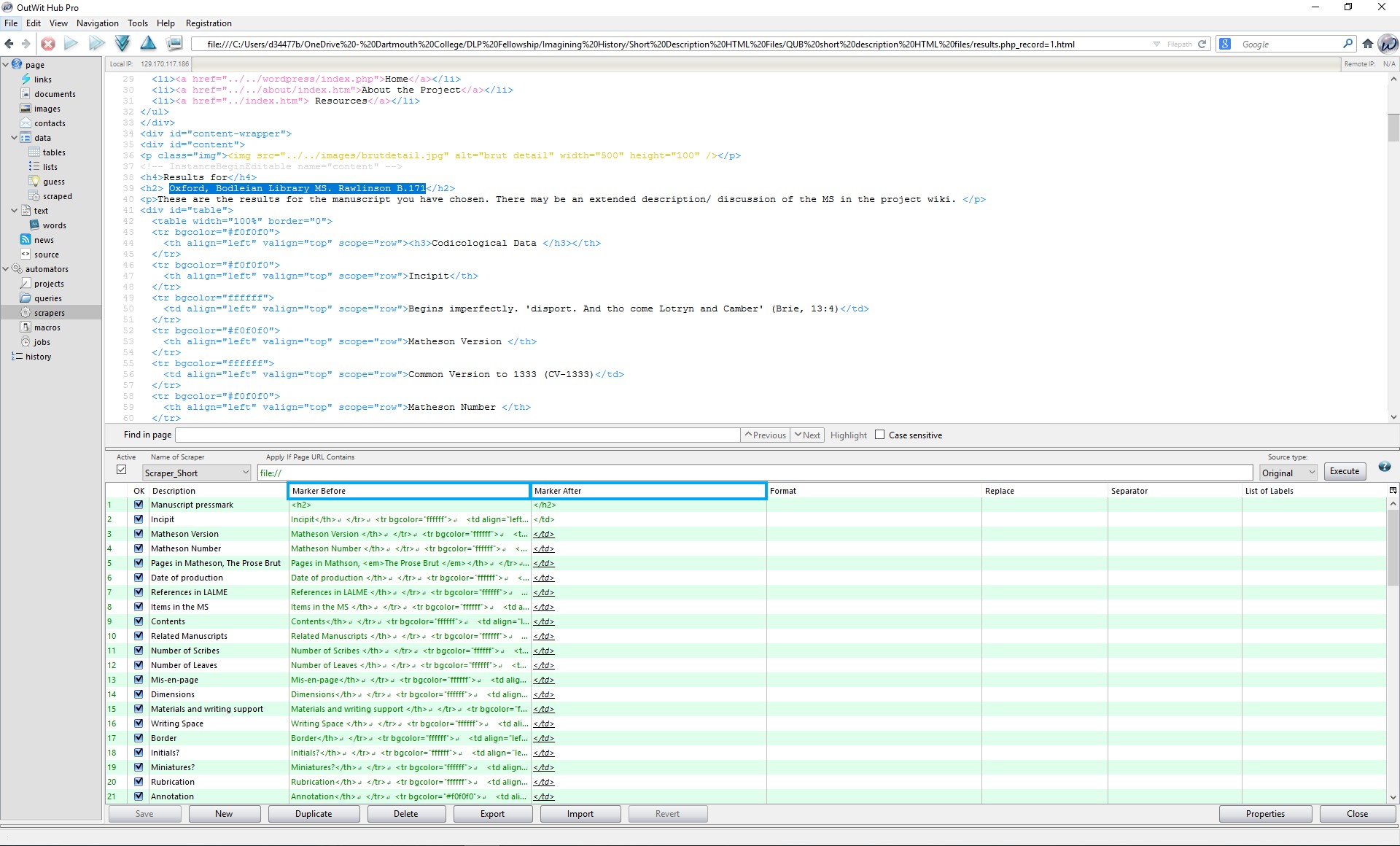
Building a custom scraper in Outwit Hub
